
관계형 DB 설계
이 글은 유튜브 생활코딩의 관계형 DB를 들으며 학습한 내용을 정리한 글입니다.
관계형 DB 설계
1) DB 설계의 개념
- 모델: 어떤 목적을 가지고 진짜를 모방한 것.
- 데이터 모델: 현실세계를 데이터로 담기 위해 현실세계를 모방한 데이터 형태.
- 데이터 모델링: 데이터 모델을 실제 데이터베이스(관계형 데이터베이스, 즉 RDB)에 넣는 작업(의 방법론).
2) 데이터 모델링의 순서
1. 업무 파악(기획)
- 데이터로 옮기고자 하는 것이 무엇인지를 명확하게 정의하는 단계. 이 단계를 통해 어떤 작업을 하는지 파악하며, 기획서를 작성하게 됨.
- 의사결정자들과 많은 회의가 필요함. 상대의 생각과 내 생각을 동기화 하는 작업을 끊임없이 해야하며, 이 단계에서 기획서와 UI를 그려보며 생각을 동기화 하는데 사용할 수 있음.
- 원하는 결과물을 만들어내기 위한 가장 중요한 작업.
- UI 기획서 제작 활용사이트: https://ovenapp.io
2. 개념적 데이터 모델링
-
내가 하고자 하는 작업들은 어떤 관계를 맺고 있는지에 대해 정리하는 것. 이 과정을 통해 ERD(ER 다이어그램)을 작성하게 됨.
-
개념적 데이터 모델링을 통해서 2가지 이점을 얻을 수 있음.
- 필터: 현실에서 개념을 추출하게 해주는 것.
- 언어: 개념에 대해서 다른 사람들과 대화하게 해주는 것.
-
ERD에 쓰이는 기호 (Entity relational diagram Helper: erd.yah.ac)
○속성 (Attribute -> column)□그룹 (Entity -> Table)◇관계 (Relation -> PK, FK / JOIN)
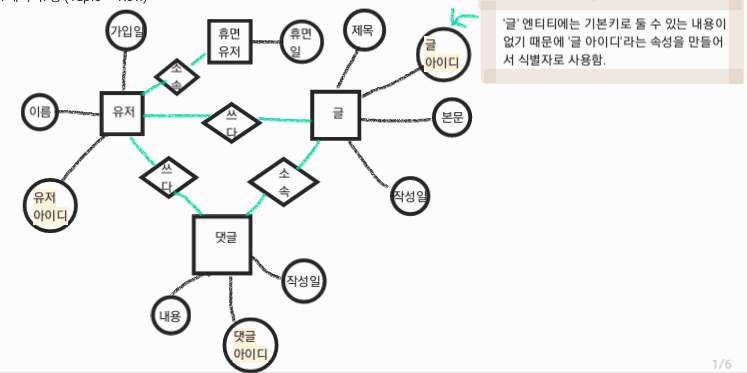
-
ERD 작성 시에는 Entity의 대표 식별자
Identifier를 선별해야 함. -
식별자는 ‘반드시 값이 있어야 함’ / ‘유일’ / ‘불변’ 의 조건을 모두 만족해야 함.
-
관계
-
1:1(일대일) 관계
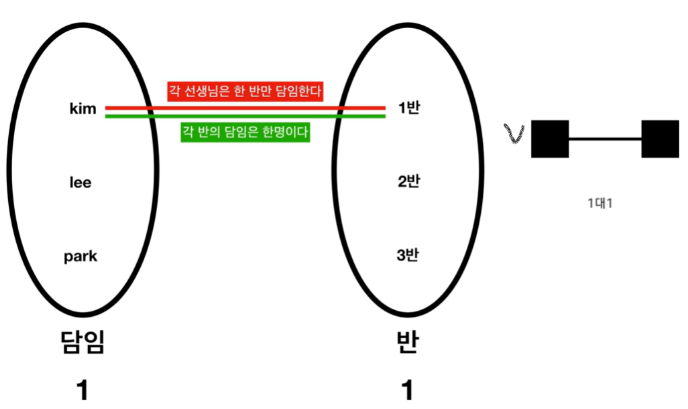
-
1:N(일대다) 관계
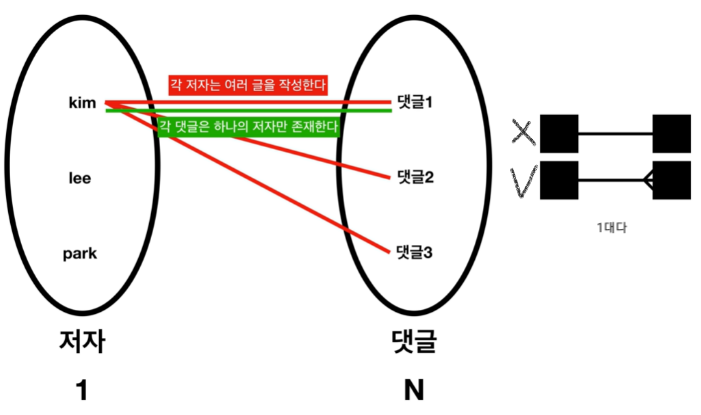
-
N:M(다대다) 관계
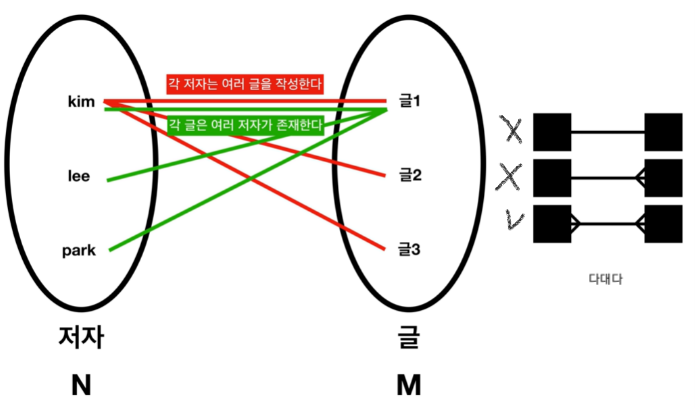
-
Mandatory와 Optional
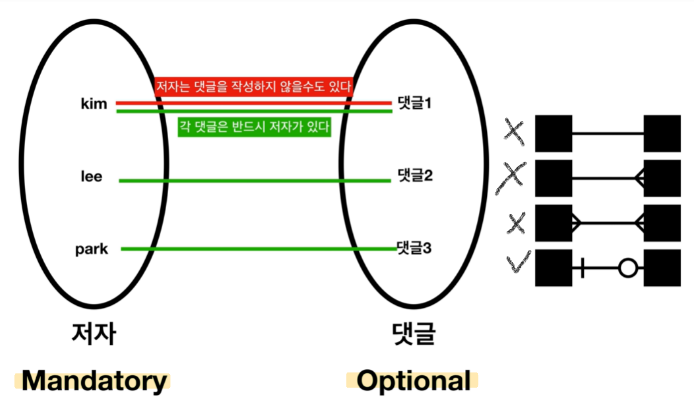
-
관계와 Optional을 반영한 ERD
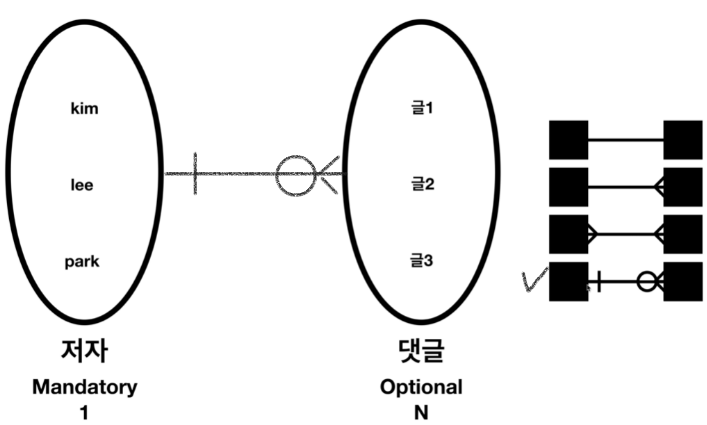
*PK와 FK?
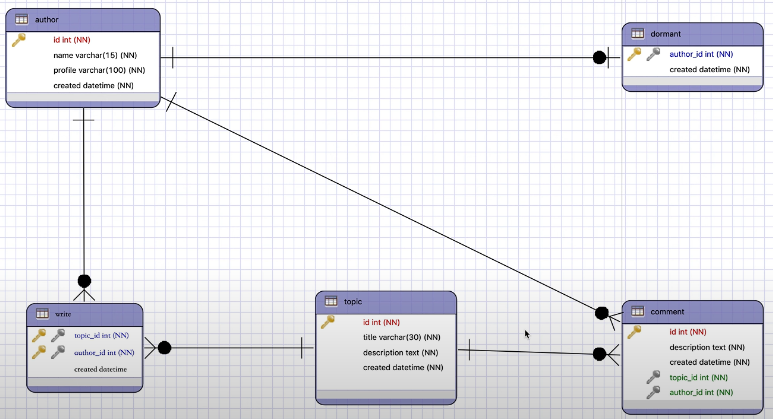
- PK : Primary Key. 자신의 테이블의 데이터를 식별할 수 있는 키.
- FK : Foreign Key. PK가 자신이 아닌 다른 테이블에 간 것. 즉, 키가 왔던 테이블로 들고가면 해당 Key를 사용하여 테이블의 데이터를 식별할 수 있다는 뜻.
-
3. 논리적 데이터 모델링
-
관계형(DB의 형태가 관계형 데이터이므로) 패러다임에 맞는 개념(즉, ERD)을 표(Table)로 전환하는 작업.
1. 1:1(일대일) 관계
-
Primary Key를 누가 가지고 있느냐. 즉, 부모 테이블이 누구이고 어떤 테이블이 부모 테이블에 의존적인지를 확인한 후, 부모테이블에 PK를 주면 됨.
-
자식 테이블에는 부모 테이블의 PK가 PK & FK 로 들어가게 됨.
2. 1:N(일대다) 관계
- 관계가 1인 테이블의 PK -> 관계가 N인 테이블의 FK로 들어가게 됨.
3. N:M(다대다) 관계
-
테이블에 다대다 관계를 매핑하여 데이터를 넣는 것은 거의 불가능함.
-
따라서 다대다 관계에서는 사이에 매개테이블(매핑테이블)을 하나 만들어서
테이블 - 일대다 - 매핑테이블 - 다대일 - 테이블로 관계를 풀어줌. -
매핑테이블은 양쪽 테이블의 PK값을 PK & FK로 갖게 됨.
4. Mandatory와 Optional
- 관계 사이에서 반드시 있어야 하는 데이터(Mandatory)와, 선택적인 데이터(Optional).
-
4. 물리적 데이터 모델링
- 실제 DB에 표(Table)를 만드는 작업. SQL 코드를 작성하게 됨.
(+추후 정규화에 대한 학습 하여 수정 예정)
마지막 수정일시: 2022-09-01 02:23
댓글남기기