
DB의 인덱스
Full Table Scan
- 원하는 자료를 찾기 위해 테이블 전체를 스캔하는 것.
- 대용량 데이터가 되면 모든 데이터에 접근해야하기 때문에 속도가 매우 느려지게 되고, 서비스에 부적합한 수준까지 내려가게 됨.
- 복잡도는 O(N)
Index(Range Scan)
-
DB에서 원하는 자료를 찾기 위한 기술.
-
인덱스는 메모리에 저장함.
-
인덱스의 구조: B-Tree(Balanced tree)
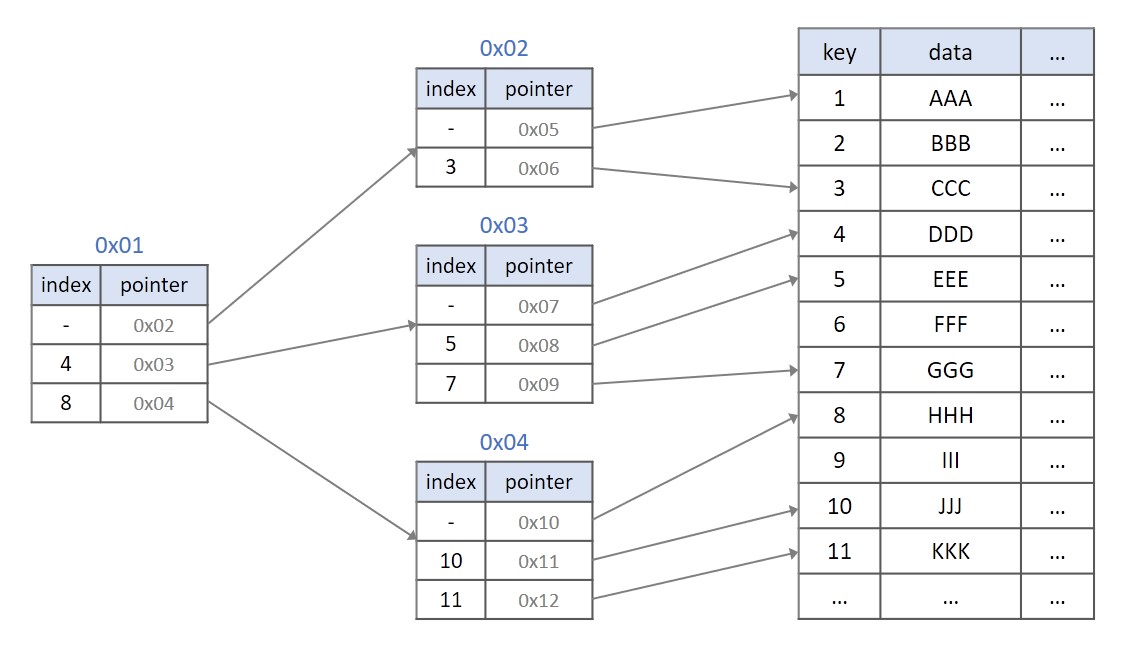
- 인덱스 조건 내용이 branch에 있고, leaf노드들에 row 데이터들이 있음.
- 필요한 조건의 값을 branch로 빠르게 찾아 들어가서 그 범위 안에 있는 row 데이터들만 스캔하는 방식.
-
복잡도는 O(logN)
언제 쓰는 것이 좋을까?
- Select (from & where) 조건에서만 사용하는 것이 좋음.
- Insert에 사용하게 되면 매번 자리를 찾아서 Insert를 하게 됨.
- 테이블이 가지고 있는 전체 데이터량의 10~15% 이내의 데이터를 꺼내올때 index를 타는 것이 성능이 좋고, 그보다 많게 되면 full 스캔이 유리하다고 함.
어떤 값을 인덱스 Column으로 쓰는 것이 좋을까?
- Cardinality(기수성, 농도)가 높은 것. 즉, 데이터가 식별이 될 수 있는 컬럼.
- ex) 성별 -> 남 / 여 로 구분됨 (전체 데이터가 10개라면 농도가 낮음)
- ex) 주민번호 -> 개인마다 데이터를 가지고 있음 (전체 데이터가 모두 가지고 있기 때문에 농도가 높음)
*클러스터와 논클러스터 방식의 정렬?
클러스터
-
인덱스에 따라 모든 데이터가 정렬되어 있다. (마치 사전처럼 데이터 자체가 인덱스라고 생각하면 됨)
-
테이블 당 하나만 생성이 가능!
CREATE TABLE member ( member_id BIGINT NOT NULL PRIMARY KEY AUTO_INCREMENT, email VARCHAR(50) NULL, ... );-
테이블에서
Primary Key로 등록을 하는 순간, member_id 열에는 클러스터형 인덱스가 자동으로 생기게 되는 것임.
-
만약 email이
Primary Key가 된다면select * from member;을 하게 되면 email 순으로 테이블이 정렬되게 된다.
-
-
범위 데이터를 긁어 오는데 특화.
-
Insert 시 최악의 경우 모든 정렬을 다시 해주어야 함.
-
예시
- 1등 - A, 2등 - B, 3등 - C …. (정렬상태)
- 1등 - D, 2등 - A, 3등 - B, 4등 - C … (자리를 다 바꾸어야 함)
논클러스터 (보조 인덱스)
- 해시맵 방식으로 데이터가 들어있다. (책 뒤에 부록처럼 인덱스 쪽이 따로 있는 것이라고 생각하면 됨)
Unique지정 시 보조 인덱스가 생성된다.Primary Key가 없고Unique Not Null이라면 해당 열은 클러스터형 인덱스가 생성된다.
- 예시
- A - 1등, B - 2등, C - 3등 … (정렬상태)
- A - 2등, B - 3등, C - 4등, D - 1등 … (데이터만 바꾸면 됨)
- 참고영상1
- 참고영상2
- 참고영상3
마지막 수정일시: 2022-11-04 01:13
댓글남기기