
MySQL 인덱스 사용과 인덱스 내부동작
1. 인덱스의 사용
-
DB의 인덱스는 기본적으로 B-Tree(Balanced Tree)구조를 가지고 있다.
-
인덱스를 검색하기 위한 일차 조건은 WHERE 절에 해당 인덱스를 생성한 열의 이름이 나와야 한다. (해당 열에 인덱스를 생성했더라도 인덱스를 사용하지 않는 경우도 많다.)
1) 인덱스 생성
## 클러스터 인덱스 -> PK 생성하는 것
create table 테이블명 (
인덱스열 primary key
);
## 보조 인덱스 (중복이 허용됨)
create index 인덱스명 ## 인덱스명은 보통 `idx_테이블명_인덱스열` 로 만듦
on 테이블명 (인덱스열);
## 유니크 인덱스 (중복이 허용 안됨 -> 데이터가 중복이 될지 안될지 꼭 유념해서 사용)
create unique index 인덱스명
on 테이블명 (인덱스열);
## 2개의 열을 가지고 인덱스 만들기
create index 인덱스명
on 테이블명 (인덱스열, 인덱스열);
analyze table 테이블명; -> 인덱스 만든 것 적용
2) 인덱스 삭제
drop index 인덱스이름 on 테이블이름;
- Tip: 인덱스를 모두 제거할때는 클러스터인덱스를 가장 마지막에 삭제해야 한다. 클러스터 인덱스를 사용하게 되면 보조인덱스를 다시 재구성하는 작업을 하게 되기 때문에 부하가 생김!
3) 인덱스 확인
## 인덱스 확인
show index from 테이블명;
## 인덱스 크기 확인
show table status like '테이블명';
-> Data_length: 클러스터 인덱스 크기
-> Index_length: 보조 인덱스 크기
** WorkBench에서 인덱스 사용했는지 확인하는 방법* - 쿼리 실행 후 Execution Plan을 누르면 ~~~ Key Lookup이라고 어떤 인덱스를 사용했는지 나옴.
2.클러스터형 인덱스 동작
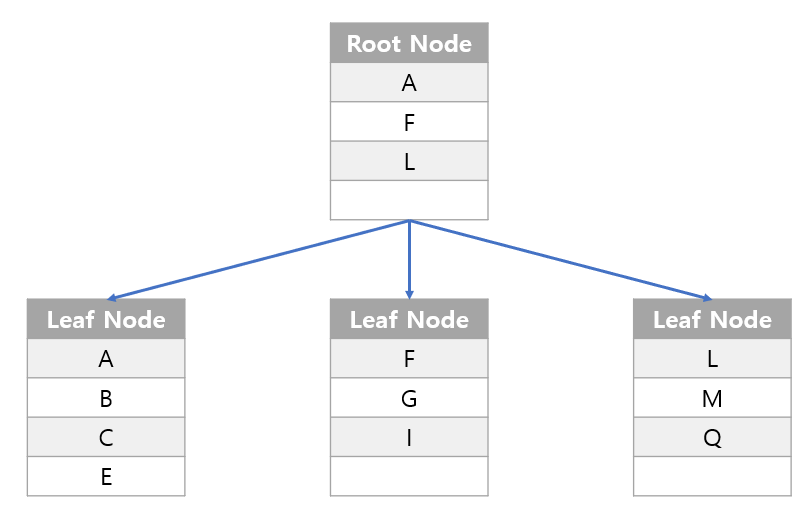
- 그림에서 보이는 테이블 하나하나를
Node, MySQL에서는페이지라고 부름. 페이지는 16KB정도의 크기이며, 인덱스 데이터가 들어간다고 봤을때는 굉장히 큰 크기.
1) 검색 시 작동
- G을 찾는다?
- 인덱스가 없을 때: A ~ G 까지 검색하게 됨.
- 인덱스가 있을 때:
Root Node에서 F을 찾은 후Leaf Node의 위치로 바로 감. 이후 해당Node에서 G를 찾음.
- 복잡도를 O(N)에서 Olog(N)으로 줄일 수 있음!
2) 데이터 변경 시 작동
-
같은
Node(페이지)에서 변동이 있는 경우는 영향 거의 없음.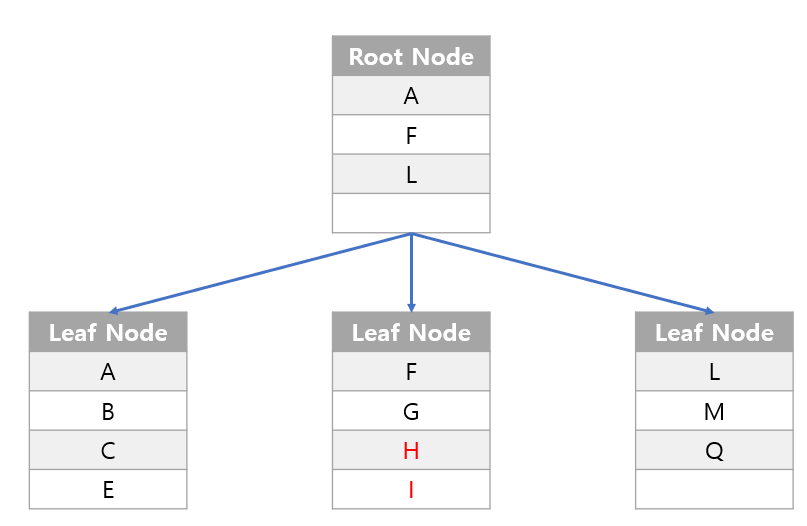
- 그림에서는 H를 삽입하기 위해 I를 뒤로 밀고 H를 넣음.
-
다른
Node(페이지)에 영향을 주고, 새로운Node(페이지)가 만들어지는 경우 부하가 많이 걸림.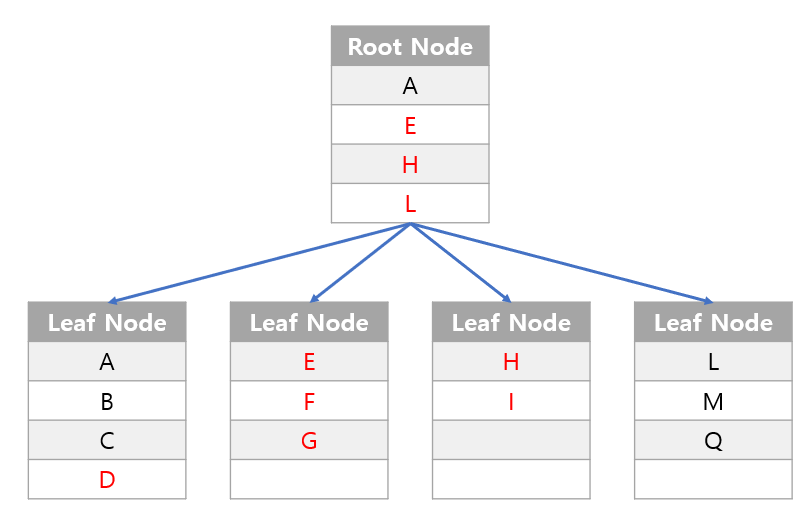
- 그림에서는 D 데이터를 넣기 위해 페이지마다의 데이터이동이 발생하고, 새로운 페이지도 생성되며, Root Node의 인덱스도 변경되게 된다.
- 즉, 이렇게 데이터의 수정, 삭제 등의 변경이 많은 경우 INDEX를 사용할 때 오히려 성능 저하가 생길 수 밖에 없다.
3. 논클러스터형 인덱스(보조 인덱스) 동작
- 데이터 영역은 그대로 두고 B-tree를 구성하고 해당 데이터들의 위치만 인덱스로 구성하게 됨.
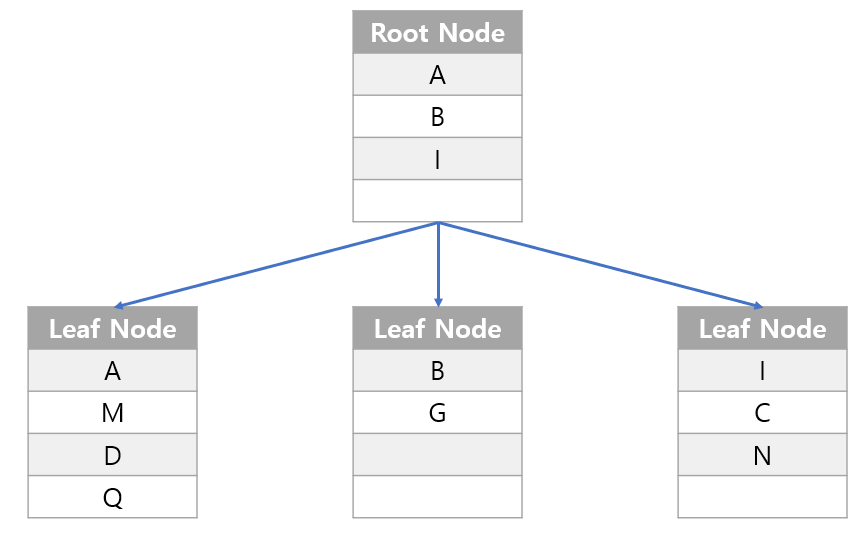
- 실제로는 Index만 궁금하다기 보다는 인덱스에 해당하는 데이터까지 다루다보니 그림에서는 이해가 잘 안되지만, Index를 통해서 해당 데이터의
위치가 어디인지를 효율적으로 찾을 수 있다는 점은Index본연의 목적에 부합함. - 보조 인덱스도 절대 느리지 않음. 데이터 삽입, 삭제 등의 데이터 변경에 있어서는 오히려 `Node(페이지)` 변화가 상대적으로 적음.
4. 정리
- 인덱스는 열 단위에 생성되며, WHERE 절에 조건으로 자주 사용될 열에 만드는 것이 가장 좋다.
-
데이터의 중복도 (Cardinality) 가 높은 열은 인덱스를 만들어도 별로 효과가 없음.
- 클러스터형
- 데이터가 정렬되므로 탐색에 최적화됨.
- 데이터 변경에서는 노드(페이지) 변경이 발생할 가능성이 높음.
- 테이블 당 1개만 생성 가능. Primary Key를 지정하지 않는다면 클러스터형 인덱스를 어디에 설정할지를 고민할 필요가 있음.
- 논클러스터형
- 데이터는 그대로 있고 인덱스가 따로 구성됨.
- 인덱스가 없는것과 클러스터형의 중간 정도에 위치한다고 생각할 수 있음.
- 테이블 당 여러개 생성이 가능(하지만, 그렇다고 남용하면 당연히 성능저하가 생김)
- 검색하는 열에만 생성하는 것이 효율적임
- 혼합도 가능하다!
- 혼합 시,
보조인덱스 - 클러스터인덱스를 찾은 후,클러스터인덱스 - 실제 데이터를 찾는 방법으로 단계를 구성하게 된다.
- 혼합 시,
-
가장 좋은 것은 없다. 데이터와 테이블의 속성에 적합한 것을 찾을 뿐.
- 참고영상
마지막 수정일시: 2022-11-04 02:45
댓글남기기