
⑨. JPQL
이 포스트 시리즈는 inflearn의 ‘‘자바 ORM 표준 JPA 프로그래밍 - 기본편 : 김영한’’ 강의와 개인적인 추가학습을 정리한 내용입니다. 해당 게시물은 이 포스트 시리즈의 마지막 게시물입니다.
9. JPQL
1) JPA가 지원하는 쿼리 방법
-
JPA Criteria
-
문자가 아닌 자바코드로 JPQL을 작성할 수 있음.
-
JPQL 빌더의 역할을 하고 JPA의 공식 기능이지만, 너무 복잡하고 실용성이 없다. (QueryDSL 이라는 더 좋은 대안이 있다.)
// 사용준비 CriteriaBuilder cd = em.getCriteriaBuilder(); CriteriaQuery<Member> query = cb.createQuery(Member.class); // 루트 클래스 Root<Member> m = query.from(Member.class); // 쿼리 생성 CriteriaQuery<Member> cq = query.select(m).where(cb.equal(m.get("username"), "kim")); List<Member> resultList = em.createQuery(cq).getReulstList();- 복잡…..
-
-
QueryDSL
//JPQL: select m from Member m where m.age > 18 JPAFactoryQuery query = new JPAQueryFactory(em); QMember m = QMember.member; List<Member> list = query.selectFrom(m) .where(m.age.gt(18)) .orderBy(m.name.desc()) .fetch();-
마찬가지로 자바코드로 JPQL 작성 가능하기 때문에 컴파일 시점에서 문법 오류를 찾을 수 있는 장점이 있음.
-
JPQL의 빌더 역할을 함.
-
동적 쿼리 작성이 편리함.
-
실무 사용 권장!!
-
실제 사용하는 방법: EntityManager와 JpaQueryFactory를
Bean으로 등록한 후 Repository에서 주입받아서 사용.(참고레퍼런스 링크: https://tecoble.techcourse.co.kr/post/2021-08-08-basic-querydsl/)
[ build.gradle ] buildscript { ext { queryDslVersion = "4.4.0" } } plugins { id 'org.springframework.boot' version '2.5.3' id 'io.spring.dependency-management' version '1.0.11.RELEASE' id 'java' } group = 'com.learning' version = '0.0.1-SNAPSHOT' sourceCompatibility = '1.8' repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-data-jpa' implementation 'org.springframework.boot:spring-boot-starter-web' runtimeOnly 'com.h2database:h2' testImplementation 'org.springframework.boot:spring-boot-starter-test' // QueryDSL implementation "com.querydsl:querydsl-jpa:${queryDslVersion}" annotationProcessor( "javax.persistence:javax.persistence-api", "javax.annotation:javax.annotation-api", "com.querydsl:querydsl-apt:${queryDslVersion}:jpa") } // QueryDSL sourceSets { main { java { srcDirs = ["$projectDir/src/main/java", "$projectDir/build/generated"] } } } test { useJUnitPlatform() }- Springboot 2.6 이상, Querydsl 5.0에서
buildscript { ext { queryDslVersion = "5.0.0" } } plugins { id 'org.springframework.boot' version '2.6.0' id 'io.spring.dependency-management' version '1.0.11.RELEASE' //querydsl 추가 id "com.ewerk.gradle.plugins.querydsl" version "1.0.10" id 'java' } group = 'study' version = '0.0.1-SNAPSHOT' sourceCompatibility = '11' configurations { compileOnly { extendsFrom annotationProcessor } } repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-data-jpa' implementation 'org.springframework.boot:spring-boot-starter-web' compileOnly 'org.projectlombok:lombok' runtimeOnly 'com.h2database:h2' //querydsl 추가 implementation "com.querydsl:querydsl-jpa:${queryDslVersion}" implementation "com.querydsl:querydsl-apt:${queryDslVersion}" annotationProcessor 'org.projectlombok:lombok' testImplementation 'org.springframework.boot:spring-boot-starter-test' } test { useJUnitPlatform() } //querydsl 추가 시작 def querydslDir = "$buildDir/generated/querydsl" querydsl { jpa = true querydslSourcesDir = querydslDir } sourceSets { main.java.srcDir querydslDir } compileQuerydsl{ options.annotationProcessorPath = configurations.querydsl } configurations { compileOnly { extendsFrom annotationProcessor } querydsl.extendsFrom compileClasspath }@Configuration public class QuerydslConfiguration { @PersistenceContext private EntityManager entityManager; @Bean public JPAQueryFactory jpaQueryFactory() { return new JPAQueryFactory(entityManager); } }@Repository @RequiredArgsConstructor public class MemberRepositoryCustom { private final JpaQueryFactory queryFactory; }
-
-
네이티브 SQL
String sql = "select ID, AGE, TEAM_ID, NAME from Member where name = 'kim'"; List<Member> resultList = em.createNativeQuery(sql, Member.class).getResultList();-
JPA가 제공하는 SQL을 직접 사용하는 기능.
-
JPQL로 해결할 수 없는 특정 DB에 의존적인 기능사용할 때 사용하기도 함. (ex, 오라클의 CONNECT BY 등)
-
-
JDBC API, MyBatis, SpringJdbcTemplate
- 함께 사용가능하나, 영속성 컨텍스트를 잘 관리해야 함.(적절한 시점에 flush 필요)
- 만약 JPA로 작업 중에는 영속성 컨텍스트에서 관리하고 있으나 DB값이 없는 상태로 직접 SQL을 활용하여 작업할 경우 값의 정합성이 맞춰지지 않는 경우가 생김.
-
JPQL(Java Persistence Query Language)
- 테이블이 아닌 엔티티 객체를 대상으로 검색하는 객체 중심의 JPA 제공 기능.
String jpql = "select m from Member m where m.name = 'kim'"; List<Member> result = em.createQuery(jpql, Member.class) .getResultList();
2) JPQL
- 엔티티 객체를 대상으로 하는 쿼리.
- 특정 DB의 SQL에 의존하지 않음.
- 사용시에 결국 SQL로 변환되지만, 그 작업을 JPA가 지원한다.
1. JPQL 기본문법
select_문:: =
select_절
from_절
[where_절]
[groupby_절]
[having_절]
[orderby_절]
update_문:: =
update_절
[where_절]
delete_문:: =
delete_절
[where_절]
- 엔티티와 속성은 대소문자 구별함. (Member, name 등)
- JPQL 키워드는 대소문자 구별 안함.(select, from, where …)
- 엔티티 이름 사용.
- 별칭 필수.
// 집합과 정렬
select
count(m), // 수
sum(m.age), // 합
avg(m.age), // 평균
max(m.age), // 최대
min(m.age) // 최소
from Member m
groupby, having
order by
-
쿼리변수
-
TypeQuery: 반환 타입이 명확할 때.
TypeQuery<Member> query = em.createQuery("select m from Member m", Member.class); TypeQuery<String> query = em.createQuery("select m.name from Member m", String.class); List<Member> result = query.getResultList(); -
Query: 반환 타입이 명확하지 않을 때.
Query qeury = em.createQuery("select m.username, m.age from Member m");
-
-
결과 조회 API
-
query.getResultList();: 결과가 하나 이상일 때, 즉 컬렉션일 때. => 결과가 없으면 빈 리스트 반환.List<Member> result = em.createQuery("select m from Member m", Member.class) .getResultList(); -
query.getSingleResult();: 결과가 정확하게 1개 일 때. 나머지는 다 익셉션 터짐.NoResultException- 결과 없음.- Spring Data JPA에서는 Optional로 반환해줌. (결국 얘도 이 익셉션을 잡아서 처리하는 것임)
NonUniqueResultException- 결과가 둘 이상임.
-
2. 파라미터 바인딩
-
이름 기준
select m from Member m where m.username = :username; query.setParameter("username", usermnameParam); // 위 :username이 "username"이고, usernameParam이 실제 값 -
위치 기준
select m from Member m where m.username = ?1; query.setParameter(1, usernameParam);- 사용 비권장. 위치가 바뀌게 되는 오류가능성이 존재.
3. 프로젝션
-
select 절에 조회할 대상을 특정하는 것을 말함.
-
대상은 엔티티, 임베디드 타입, 스칼라 타입(기본 값)이 될 수 있음.
select m from Member m // 엔티티 select m.team from Member m // m에 있는 team 엔티티 => 이런 경우 명시적으로 team을 쿼리에서 보이게 하는 것이 좋음. => select t from Member m join m.team t select m.address from Member m // address 임베디드 타입 select m.username, m.age from Member m // 스칼라 타입 -
select 뒤에
distinct로 중복 제거 가능.
- 프로젝션으로 여러 값 조회
-
select m.username, m.age from Member m-
Object[] 타입으로 조회
List<Object[]> resultList = em.createQuery("select m.username, m.age from Member m") .getResultList(); Object[] result = resultList.get(0); => result[0] : m.username => result[1] : m.age -
new 명령어로 조회 : DTO로 바로 조회
List<MemberDTO> = em.createQuery("select new 패키지명(전체).MemberDTO(m.username, m.age) from Member m") .getResultList(); MemberDTO memberDto = result.get(0); => memberDto.getUsername() : m.username => memberDto.getAge() : m.age- 이럴 경우 MemberDTO에 생성자가 필요함.
-
4. 페이징 API
-
페이징: 몇 번째부터 몇 개?
setFirstResult: 몇 번째부터?setMaxResults: 몇 개?
String jpql = "select m from Member m order by m.name desc"; List<Member> resultList = em.createQuery(jpql, Member.class) .setFirstResult(0) // 처음부터 .setMaxResults(10) // 10개 .getResultList();- 설멍마다의 방언이 적용이 됨.
5. 조인
-
내부 조인: 두 테이블에 데이터가 다 있을때 출력.
select m from Member m join m.team t -
외부 조인: 한쪽만 데이터가 있으면 출력. 대신 빈칸은 null로 데이터가 채워짐.
select m from Member m left join m.team t -
세타 조인: 막 조인하는것.
select count(m) from Member m, Team t where m.username = t.name -
ON절 : 조회 대상 필터링[JPQL] select m, t from Member m join m.team t on t.name = 'teamA' => [SQL] select m.*, t.* from Member m join Team t on m.Team_ID = t.id and t.name = 'teamA' [JPQL] select m, t from Member m join Team t on m.username = t.name => [SQL] select m.*, t.* from Member m join Team t on m.username = t.name
6. 서브 쿼리
-
쿼리 내부의 쿼리
// teamA 소속인 회원 select m from Member m where exists(select t from m.team t where t.name = 'teamA') // 한 건이라도 주문한 고객 select m from Member m where (select count(o) from Order o where m = o.member) > 0 -
JPA에서 서브쿼리는 WHERE, HAVING절에서만 사용이 가능함.
-
하이버네이트는 SELECT절도 가능. (우리 대부분이 가능할 것)
-
FROM절의 서브쿼리는 불가능하여 JOIN으로 해결해야 함.
7. 조건식 - CASE 식
select
case when m.age <= 10 then '학생요금'
when m.age >= 50 them '경로요금'
else '일반요금'
end
from Memeber m
[coalesce : 하나씩 조회해서 null이 아니면 반환]
select coalesce(m.username, '이름 없음') from Member m
// 사용자 이름이 없으면 '이름 없음' 반환
[nullif : 두 값이 같으면 null 반환, 다르면 첫번째 값 반환]
select nullif(m.username, '관리자') from Member m
// 사용자 이름이 '관리자'면 null 반환, 아니면 이름 반환
8. 기본 함수
CONCAT문자 더함SUBSTRING문자 범위TRIM공백 제거LOWER,UPPERLENGTHLOCATE문자의 시작위치 반환 / locate (‘a’, create) == > 3size컬렉션 크기 리턴index@OrderColumn 쓸 때 위치값 구할때 사용
9. 사용자 정의 함수
-
함수를 등록한 후 설정파일에서 설정해주면 사용 가능.
<property name="hibernate.dialect" value="사용자 정의함수 패키지명.클래스명" />public class 클래스명 extends 기존에 사용하는 DB의 DB방언 상속 { public 클래스명() { registerFunction("사용자 정의함수 이름". new StandardSQLFunction("사용자 정의함수 이름", StandardBasicTypes.STRING)); } }- 이 형태는 외우기보다는 DB방언 클래스 들어가면 소스코드로 나와있음.
select function('사용자 정의함수 이름', i.name) from Item i // 이렇게 사용
10. 경로 표현식
-
. 으로 객체 그래프를 탐색하는 것.
-
상태 필드
[JPQL] select m.username from Member m [SQL] select m.username from Member m- 경로의 마지막 단이라 더이상 탐색 X.
-
단일 값 연관 경로 탐색
[JPQL] select o.Member from Order O [SQL] select m.* from Order o join Member m on o.member_id = m.id- 이렇게 묵시적 조인이 발생함(내 코드에는 없던 join이 sql로 변환되면서 생김)
- 작동에는 당연히 필요하나 코드 단에서는 확인이 어려워 유지보수나 쿼리튜닝이 어려워짐 -> 실무에서는 명시적 조인이 되도록 바꿔서 사용하는 것 권장.
select m from Member m join Order o on o.member_id = m.id
-
3) 페치 조인(fetch join)
-
SQL 조인 종류가 아니라 JPQL에서 성능 최적화를 위해 제공하는 기능.
-
핵심개념 - ‘연관된 엔티티나 컬렉션을 SQL 한방 쿼리로 함께 조회’
[엔티티 페치조인] String jpql = "select m from Member m join fetch m.team"; List<Member> members = em.createQuery(jpql, Member.class) .getResultList(); for(Member m : members) { System.out.println("username = " + m.getUsername() + "teamName = " + m.getTeam().name()); }- 기본 세팅을 지연로딩(LAZY)로 하기 때문에, 프록시로 로딩 되었다가 사용 시점에 쿼리가 한번 더 나가게 됨.
- 성능의 저하가 있을 수 있기 때문에 의도하고자 하면
fetch join으로 연관된 엔티티나 컬렉션을 한번에 가져오도록 함. 명시적이기 때문에LAZY세팅보다페치조인이 우선순위를 가져감.
[컬렉션 페치조인] String jpql = "select t from Team t join fetch t.members where t.name = '팀A'"; List<Team> teams = em.createQuery(jpql, Team.class) .getResultList(); for(Team t : teams) { System.out.println("teamname = " + team.getName() + ", team = " + team); for(Member m : team.getMembers()) { System.out.println("---> username = " + m.getUsername() + "member = " + m); } } -
fetch join의 문제점
- 위 상황에서 Team이 겹치는 맴버가 있다면 해당 값이 중복으로 조회되게 됨.
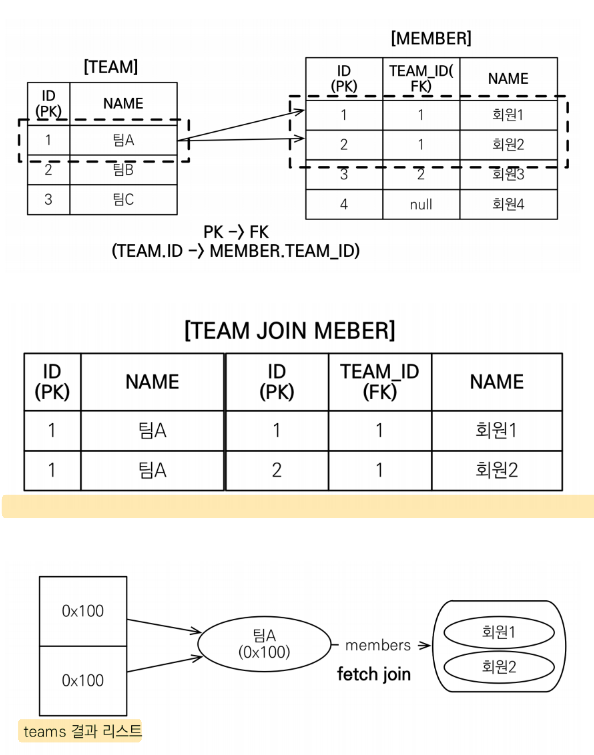
// 출력예시
teamname = 팀A, team = 객체주소
---> username = 회원1, member = 객체주소
---> username = 회원2, member = 객체주소
teamname = 팀A, team = 객체주소
---> username = 회원1, member = 객체주소
---> username = 회원2, member = 객체주소
-
해결방안
DISTINCT중복제거기능. 단, JPA에서는 SQL에서만 DISTINCT를 수행하는 것이 아니라 애플리케이션 엔티티를 확인하여 중복제거까지 수행함.- SQL에 DISTINCT 추가 (SQL 단위에서는 테이블 내에 모든 데이터가 똑같아야 걸러짐)
- 애플리케이션에서 엔티티 중복 제거 (애플리케이션 단위에서는 같은 참조값을 가진 엔티티까지 걸러짐)
[DISTINCT 추가] String jpql = "select DISTINCT t from Team t join fetch t.members where t.name = '팀A'"; List<Team> teams = em.createQuery(jpql, Team.class) .getResultList(); for(Team t : teams) { System.out.println("teamname = " + team.getName() + ", team = " + team); for(Member m : team.getMembers()) { System.out.println("---> username = " + m.getUsername() + "member = " + m); } } // 출력 teamname = 팀A, team = 객체주소 ---> username = 회원1, member = 객체주소 ---> username = 회원2, member = 객체주소 -
페치조인과 실무
-
페치 조인 대상에게는 별칭을 줄 수 없음. 이는 페치조인의 핵심개념인 ‘나와 연관된 것을 한 방 쿼리로 가져온다’는 의도에 위배되기 때문. 그 중에서 별칭을 통해 탐색을 하게 되면 나머지 데이터들이 누락되거나 갈 곳을 잃을 가능성이 많아짐.
-
둘 이상의 컬렉션은 페치조인 불가능.
-
컬렉션 페치조인 시 페이징 불가능. (마찬가지 이유로 위험)
-
@BatchSize(size = n)엔티티에 설정하면 메모리에 배치사이즈만큼 쿼리를 한번에 보내게 됨. => 페치조인을 하지 못하는 경우라도 지연로딩 횟수를 줄일 수 있음.-
실무에서는 배치사이즈를 글로벌 세팅으로 해놓고 사용하는 경우가 많음.
<property name="hibernate.default_batch_fetch_size" value="1000" /> // 보통 1000 이하로
-
-
정리: 객체 그래프를 유지할 때 사용하면 효과적임. 만약 여러 테이블을 조인해서 엔티티가 가진 모양 그대로가 아닌 다른 결과를 내야한다면 일반 조인을 사용하여 DTO로 반환하는 것이 효과적임.
-
4) 엔티티 직접 사용
-
JPQL에서 엔티티를 직접 사용하게 되면 SQL에서 해당 엔티티의 기본 키 값을 사용하게 됨.
[엔티티 파라미터] String jpql = "select m from Member m where m = :member"; List resultList = em.createQuery(jpql) .setParameter("member", member) .getResultList(); [식별자 파라미터] String jpql = "select m from Member m where m.id = :memberId"; List resultList = em.createQuery(jpql) .setParameter("memberId", memberId) .getResultList();-
똑같음
=> SQL select m.* from Member m where m.id=?
-
-
외래 키 사용도 동일함.
5) Named 쿼리
- 미리 정의해서 사용하는 JPQL의 정적 쿼리.
- 어노테이션과 XML 두가지 방법이 있으며, 애플리케이션 로딩 시점에 쿼리를 검증해줌!! (Syntax 익셉션 발생)
[어노테이션 사용]
@Entity
@NamedQuery(
name = "Member.findByUsername",
query = "select m from Member m where m.username = :username")
public class Member {
...
}
List<Member> resultList = em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", "회원1")
.getResultList();
[xml설정 사용] -> 항상 우선권 가짐

-
Spring Data JPA에서는 인터페이스메서드 위에 바로 선언이 가능함.
@Query("select * from Member") ...
6) 벌크 연산
- 쿼리를 직접 사용.
executeUpdate()메서드 사용. - 벌크연산은 영속성 컨텍스트를 거치지 않고 바로 SQL쿼리가 날아감.
- 영속성 컨텍스트 특성 상, SQL 쿼리가 날아가면 기존에 ‘쓰기 지연 SQL’에 있던 쿼리까지 같이 날아감.
- 단, 그렇게 된다고 영속성 컨텍스트가 비워지는 것이 아니기 때문에 벌크연산 수행 후에는 반드시 영속성 컨텍스트를 초기화해주어야 함.
Member member1 = new Member();
member1.setUsername("회원1");
member1.setAge(0);
member1.setTeam(teamA);
em.persist(member1);
int resultCount = em.createQuery("update Member m set m.age = 20")
.executeUpdate(); // 1건 반영
em.clear(); // 영속성 컨텍스트 초기화
Member findMember = em.find(Member.class, member1.getId());
// 초기화 되었기 때문에 이때 쿼리가 날아가서 데이터를 영속성 컨텍스트에 올림.
System.out.println("findMember age = " + findMember.getAge()); // 20
// 만약 영속성 컨텍스트 초기화 안하면 1차캐시에 있는 0이 출력되게 됨.
마지막 수정일시: 2022-10-18 02:21
댓글남기기